Regular Expressions in Python: A Comprehensive Tutorial for Beginners
Regular expressions, also known as "regex" or "regexp", are a powerful tool for manipulating text and data
Software Engineer & Technical Writer
Welcome to this tutorial on regular expressions in Python! Regular expressions, also known as "regex" or "regexp", are a powerful tool for manipulating text and data. They are a sequence of characters that define a search pattern and are mainly used for string matching and text manipulation.
In Python, you can use the re module to work with regular expressions. In this tutorial, we will go over the basics of regular expressions and how to use them in Python.
Importing the re module
The first step in working with regular expressions in Python is to import the re module. You can do this by adding the following line at the beginning of your Python script:
import re
Defining a Regular Expression Pattern
The re module provides the compile() function, which is used to create a regular expression pattern. The compile() function takes a string as its argument, which represents the regular expression pattern. For example, the following code creates a regular expression pattern that matches strings that begin with the word "Hello":
pattern = re.compile('^Hello')
In this example, ^ is a special character called an anchor. It's used to specify the position of the pattern in the string, in this case, the start of the string.
Matching Patterns in a String
Once you have defined a regular expression pattern, you can use it to search for matches in a string. The re module provides several functions for this purpose, such as search(), findall(), and finditer().
- The
search()function searches for the first occurrence of the pattern in the string, and returns amatchobject if the pattern is found, orNoneotherwise. For example, the following code searches for the pattern we defined earlier in the string "Hello, world!":
result = pattern.search('Hello, world!')
print(result) # <re.Match object; span=(0, 5), match='Hello'>
As you can see, the search() function returns a match object that contains information about the match, such as the start and end positions of the match and the matching string.
- The
findall()function finds all occurrences of the pattern in the string and returns them as a list of strings. For example:
result = pattern.findall('Hello, world!Hello')
print(result) # ['Hello','Hello']
- The
finditer()function finds all occurrences of the pattern in the string and returns them as an iterator of match objects. This can be useful if you need to iterate over the matches and access the match information.
result = pattern.finditer('Hello, world!Hello')
for match in result:
print(match.start(), match.end(), match.group())
Replacing Patterns in a String
The re module also provides the sub() function, which can be used to replace all occurrences of a pattern in a string with a replacement string. The sub() function takes two arguments: the replacement string and the input string, and returns a new string with the replacements. For example:
result = pattern.sub('Hi', 'Hello, world!Hello')
print(result) # 'Hi, world!Hi'
Special Characters and Groups
Regular expressions include special characters and groups to match specific types of characters or to extract specific parts of the match. Here are some examples of common special characters and groups:
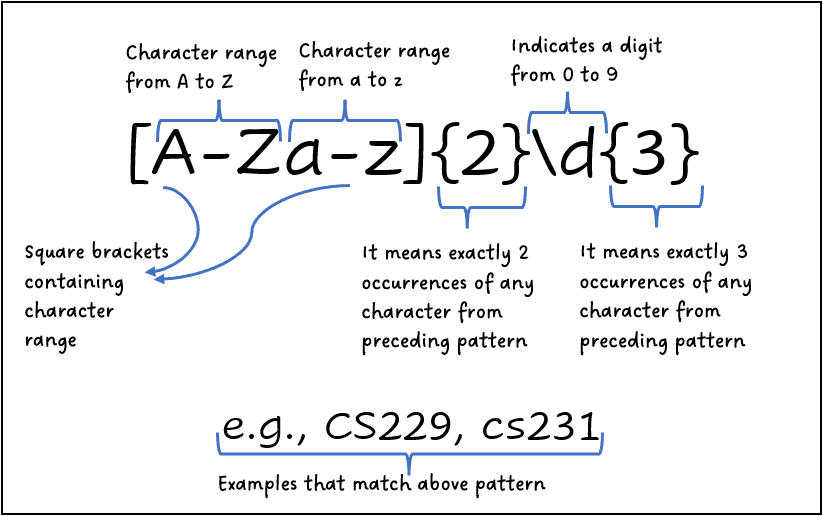
\d: Matches any digit (0-9).\w: Matches any word character (a-z, A-Z, 0-9, and _).\s: Matches any whitespace character (space, tab, newline, etc.).[]: Matches any character inside the square brackets. For example,[abc]matches "a", "b", or "c".(): Grouping characters and can be used to extract specific parts of the match.
For example, the following code creates a regular expression pattern that matches strings of digits:
pattern = re.compile('\d+')
result = pattern.findall('Here are some numbers: 42, 123, 5')
print(result) # ['42', '123', '5']
And the following code creates a regular expression pattern that matches strings that begin with the word "Hello" and have a word after it:
pattern = re.compile('(Hello) (\w+)')
result = pattern.search('Hello, world!')
print(result.group(1)) # 'Hello'
print(result.group(2)) # 'world'
Conclusion
Regular expressions are a powerful tool for manipulating text and data in Python. The re module provides many functions and options for working with regular expressions, and the special characters and groups allow you to match and extract specific parts of the text.
Keep in mind that regular expressions can be complex and difficult to read, and it's important to test your regular expressions with different inputs to make sure they work as expected. There are many resources available online to learn more about regular expressions and their syntax.
I'd love to connect with you via Twitter & LinkedIn
Happy hacking!