Introduction to Hash Tables: A Beginner-Friendly Guide | Day #18
Software Engineer & Technical Writer
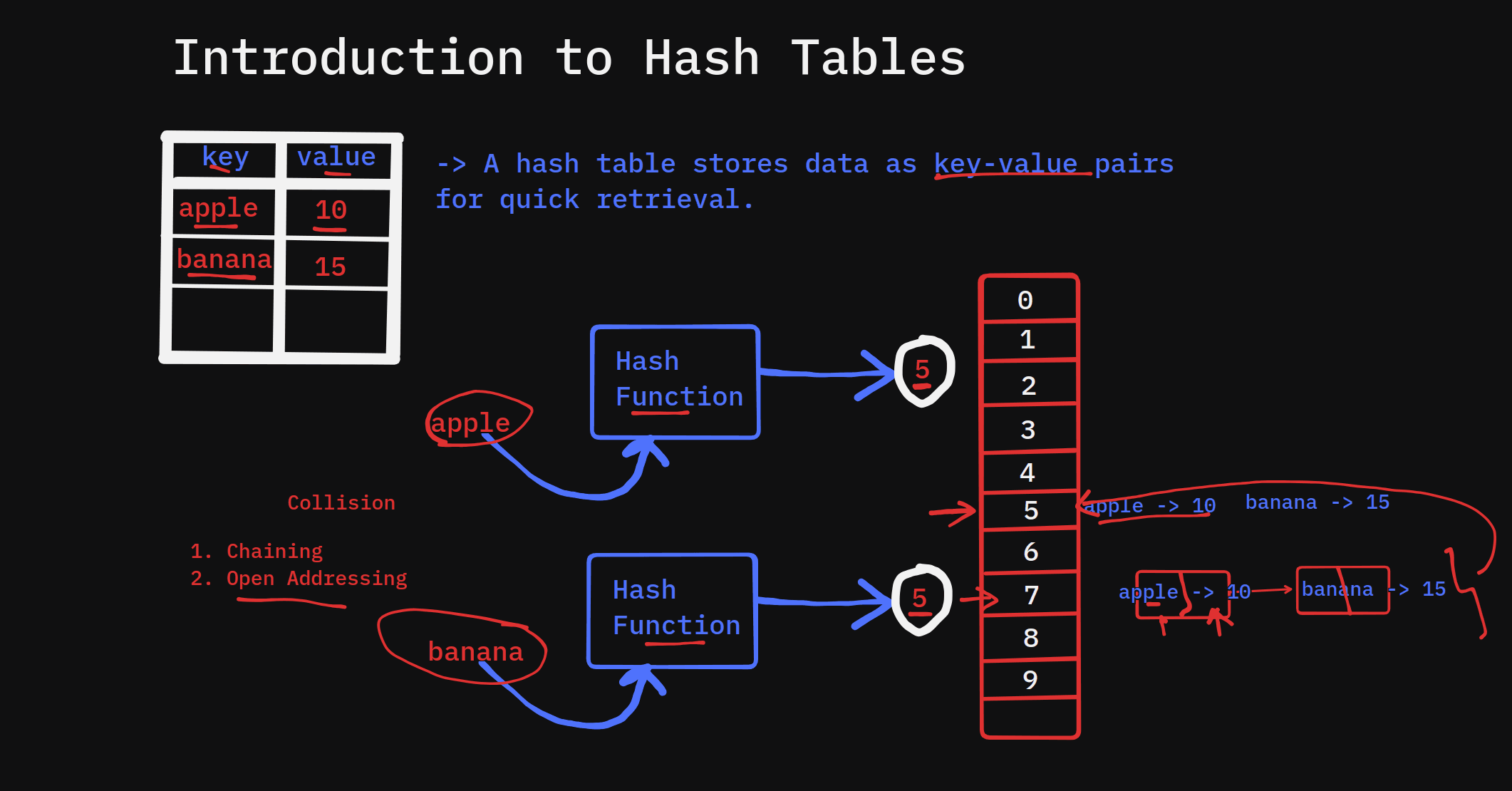
A hash table is a data structure that stores key-value pairs, providing efficient data retrieval in constant time, O(1), in most cases. It maps keys to values using a hash function, making it a fundamental component in computer science for storing and managing data.
Hash tables are widely used across various real-world applications like caching in web browsers, databases, and look-up tables in compilers, due to their fast insertion and search capabilities.
How Hash Tables Work
At the core of a hash table is a hash function. This function takes a key (like a string or number) and converts it into an index within a fixed-size array (also known as a bucket). Here’s a step-by-step breakdown:
Key-Value Pair Storage: Each element consists of a key and a corresponding value. For example,
("name", "Alice")maps the key"name"to the value"Alice".Hash Function: The key is processed through a hash function, which generates a numerical value (hash code) that corresponds to an index in the array.
Storing the Data: The value is placed at the computed index. If two keys result in the same index (collision), additional logic is applied (explained in the next section).

Handling Collisions in Hash Tables
What is a Collision?
A collision occurs when two different keys produce the same hash index. Since multiple values cannot occupy the same bucket directly, hash tables use collision-handling strategies.
Collision-Handling Strategies
Chaining:
Each bucket contains a linked list of key-value pairs.
If a collision occurs, the new element is added to the list at that index.
Open Addressing:
- In this method, if a collision occurs, the algorithm searches for the next available bucket using techniques like linear probing or quadratic probing.
Advantages and Limitations of Hash Tables
Advantages
Fast Lookups: Hash tables offer average-case O(1) time complexity for search, insertion, and deletion.
Flexible Keys: Keys can be any data type, such as strings or numbers.
Widely Used: Foundational to many systems like dictionaries in Python or maps in JavaScript.
Limitations
Collisions: Can reduce performance if poorly managed.
Resizing: Hash tables need resizing as they fill up, which is an expensive operation.
Hash Function Quality: A poorly designed hash function can lead to uneven key distribution.
Real-World Applications of Hash Tables
Caching in Web Browsers and APIs
- Web browsers use hash tables to store cached data, allowing for faster page loading.
Symbol Tables in Compilers
- Compilers use hash tables to store variable names and their associated values or data types.
Databases and Search Engines
- Databases use hash tables to index and retrieve data efficiently.
Implementation Examples
Python Code Example
# Creating a simple hash table using a dictionary
hash_table = {}
hash_table["name"] = "Alice"
print(hash_table["name"]) # Output: Alice
In Python, the built-in dictionary data type is a hash table. In this example, the key "name" is mapped to the value "Alice".
JavaScript Code Example
// Creating a hash table in JavaScript
const hashTable = {};
hashTable["name"] = "Alice";
console.log(hashTable["name"]); // Output: Alice
JavaScript’s objects serve as hash tables, allowing key-value pairs to be added and accessed quickly.
Time Complexity Analysis
The performance of a hash table depends on its ability to manage collisions effectively.
Average Case:
Insertion: O(1)
Search: O(1)
Deletion: O(1)
Worst Case (when many collisions occur):
- Insertion/Search/Deletion: O(n), where n is the number of elements.
In well-designed hash tables, the average case dominates, and operations are extremely fast.
Hash Tables vs. Other Data Structures
Hash Table vs. Array:
Arrays provide O(1) access by index, but require elements to be stored in sequential memory.
Hash tables offer faster lookups by key but at the cost of potential collisions.
Hash Table vs. Linked List:
Linked lists allow dynamic memory usage but have O(n) search time.
Hash tables provide faster access but need more space for buckets.
Hash Table vs. Dictionary:
- In Python, dictionaries are hash table implementations with built-in collision handling and resizing.
Conclusion
Hash tables are a powerful data structure used extensively in software development for their speed and flexibility. By mapping keys to values using a hash function, they enable fast lookups and efficient data management. Understanding how hash tables work, including handling collisions and resizing, is essential for developers working with caching systems, databases, and real-time applications.
Call to Action
Try implementing your own hash table from scratch to gain a deeper understanding of how they work. Experiment with different hash functions and collision-handling strategies, and see how performance changes with larger datasets. Share your implementations and any questions in the comments below!